Cloud statistics#
Computing statistics of consecutive cloudy segments in a dataset can be challenging to implement efficiently in Python. Here are some ideas which show how this can be done in a vectorized (i.e. numpy friendly) way.
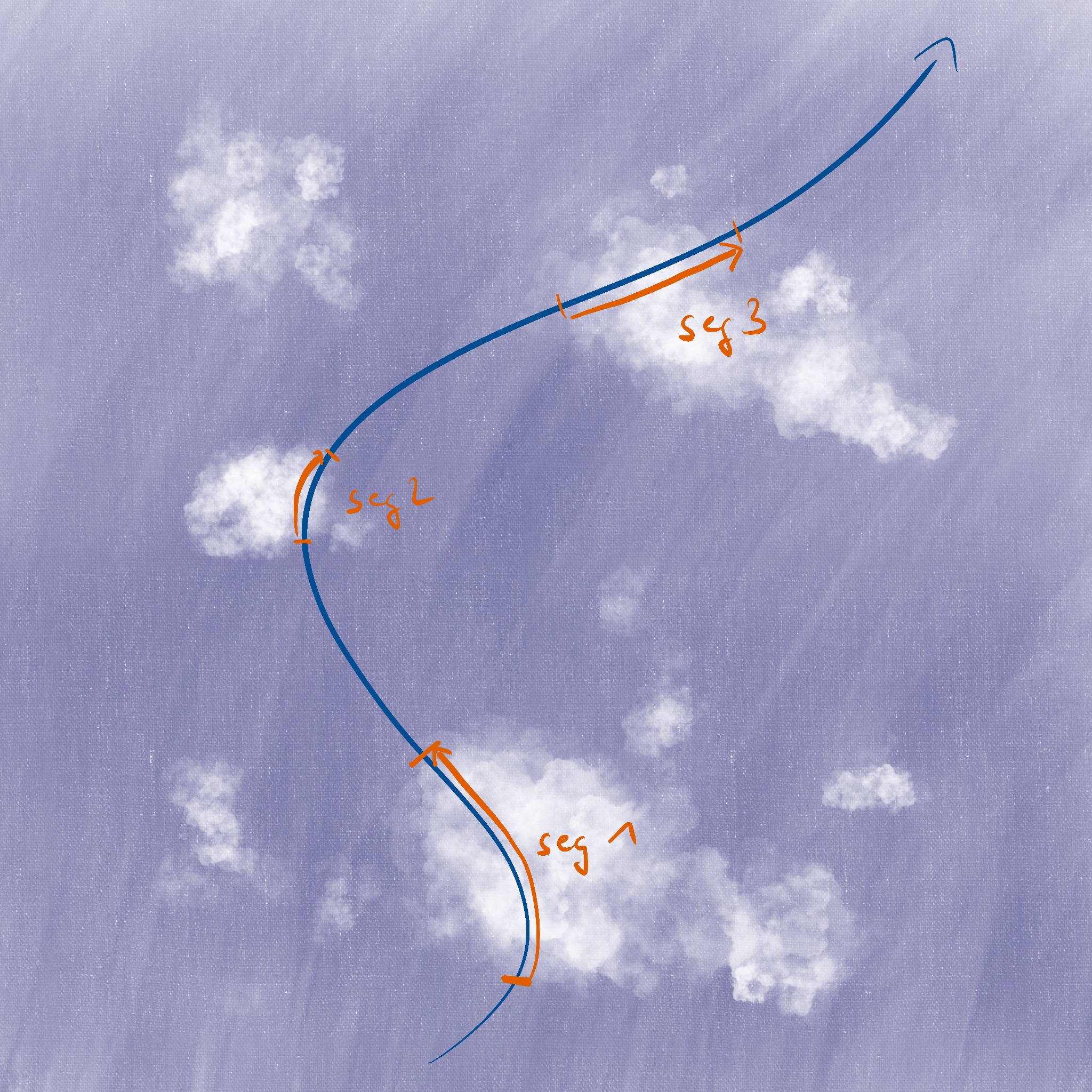
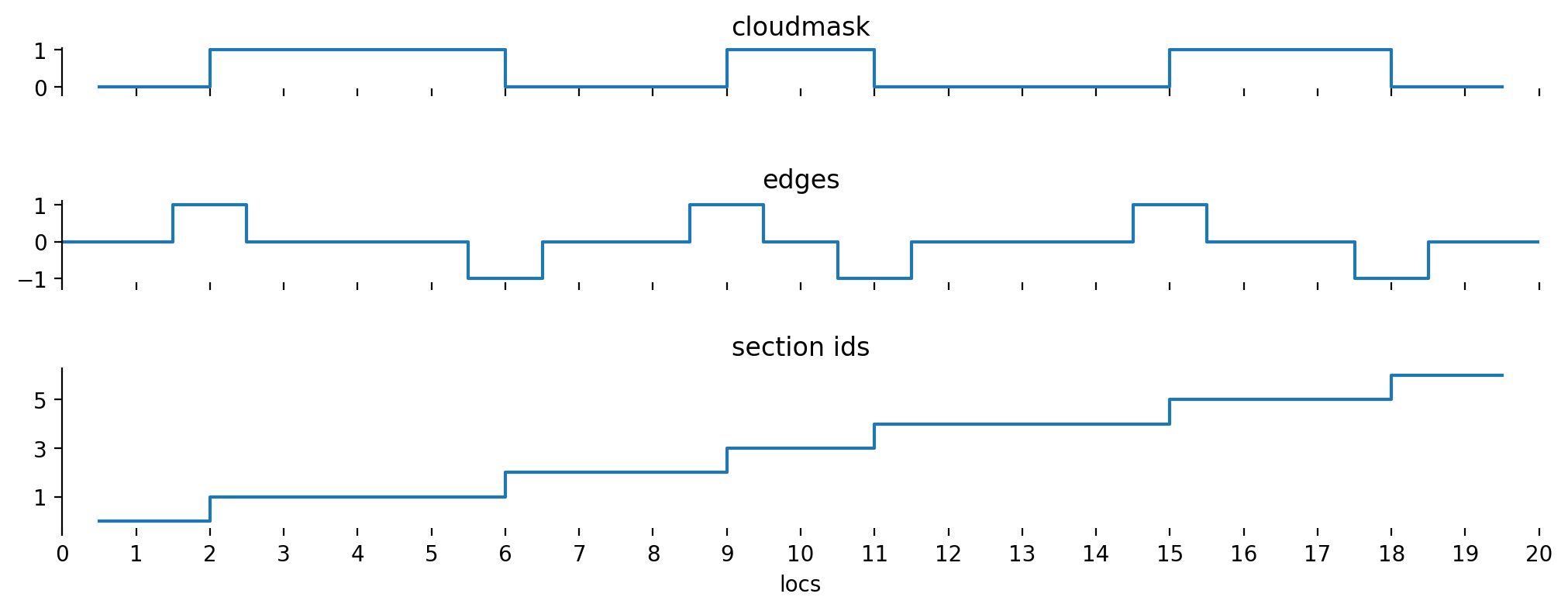
This chapter assumes that a cloud mask and possibly other cloud-related parameters are defined on a 1D trajectory as shown as blue line in the following illustration. We are interested in analysing those parameters per consecutive cloudy segment (indicated in orange).
Cloud length#
Cloud length is the distance along the trajectory from start to end of a cloudy region. Let’s look at the trajectory from above, but laid out as a straight line:

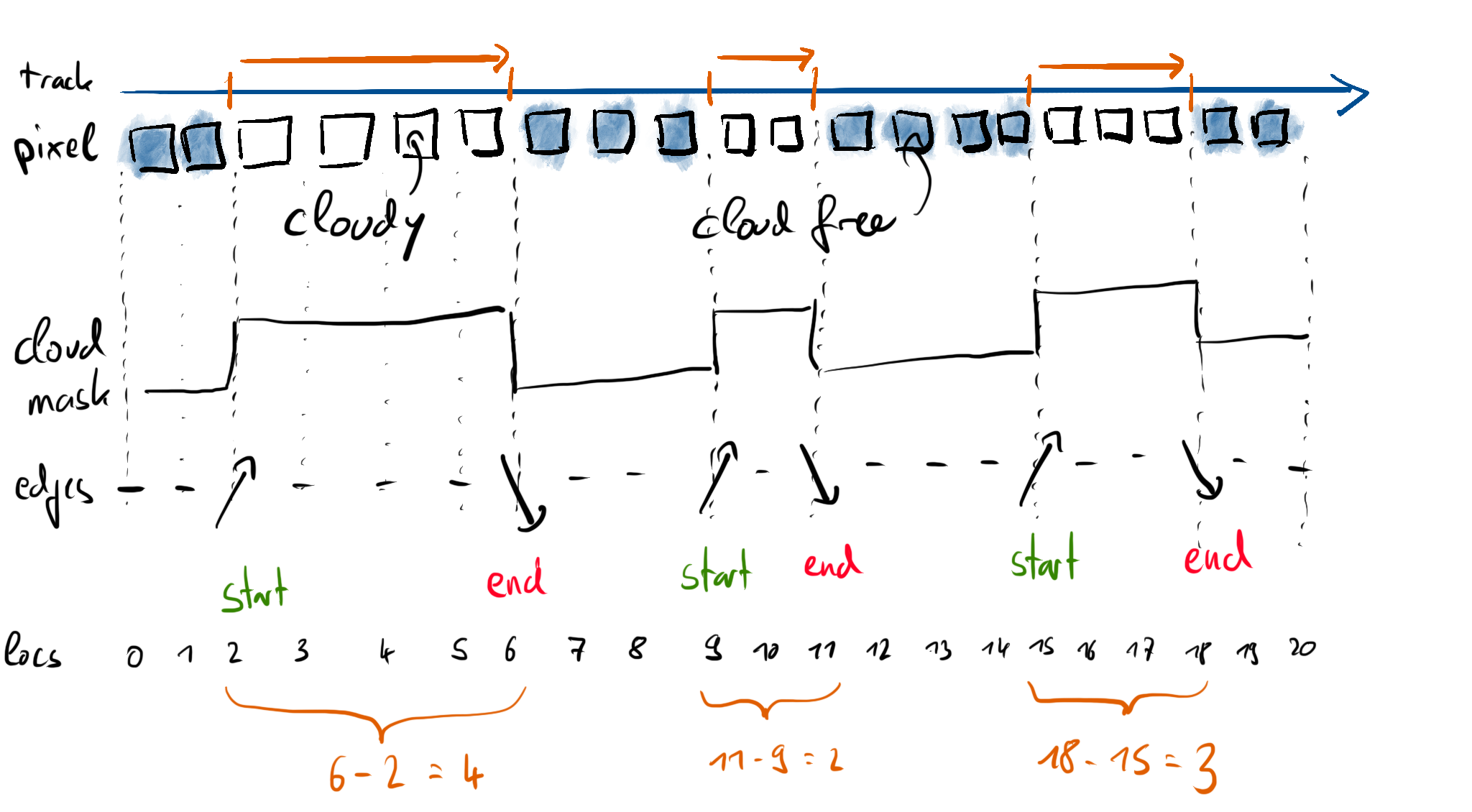
We’ve got the track on the top as well as an indication of the start and end of our cloud segments. The sensor will usually capture data in some form of pixels. In this example, we depict non-cloudy pixels in blue and cloudy pixels in white. We’ll now assume that we know a cloud mask defined on these pixel locations which takes a value of 1 on cloudy pixels and a value of 0 on cloud free pixels:
Let’s define this cloud mask according to the figure above. We’ll use boolean values here and convert them to integers later on.
cloudmask = np.array([
False, False,
True, True, True, True,
False, False, False,
True, True,
False, False, False, False,
True, True, True,
False, False
])

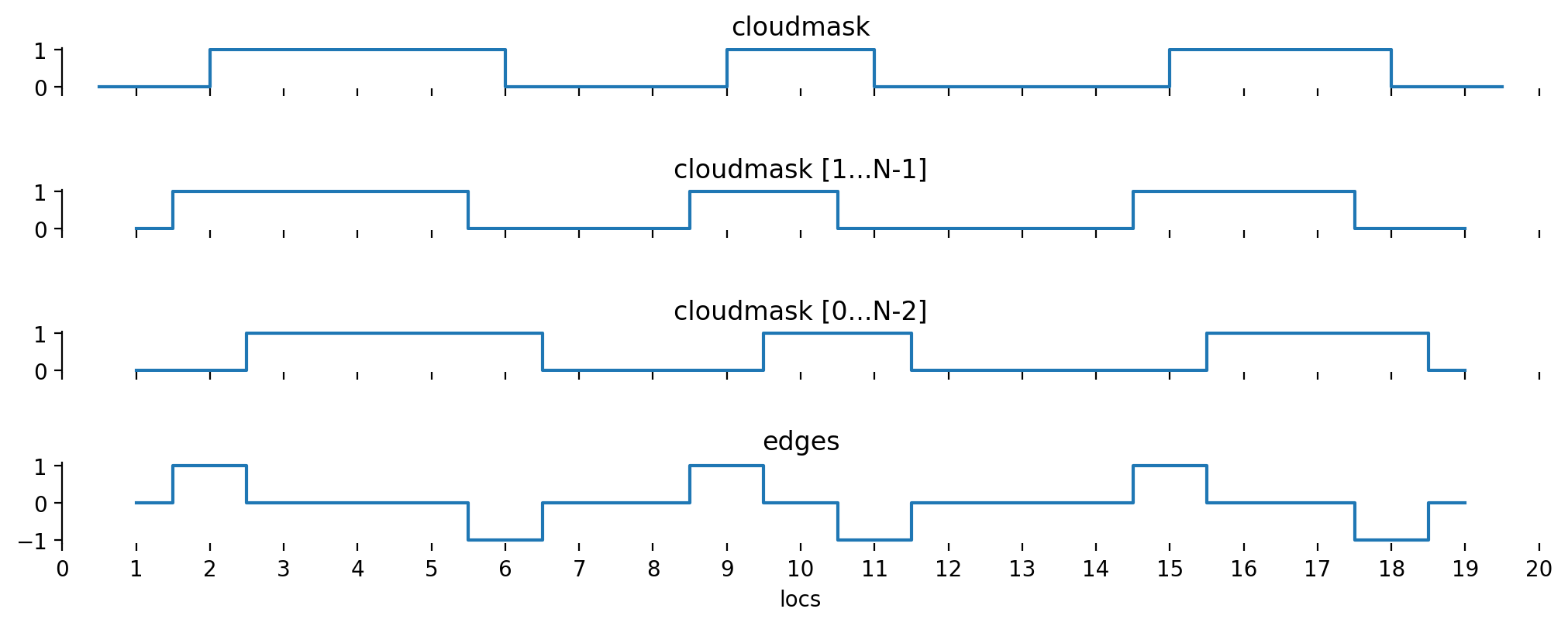
Based on this flag, it is possible to derive cloud edge locations \(E\) by shifting \(C\) by one and subtracting from itself:
that way, we end up with three possible values for the edges:
These two shifted subsets are best visualized by thinking of two shifts about half a pixel in opposite directions. Subtracting the two leads to the cloud edges:
Note
Shifting both subsets by half a pixel (in stead of shifting one subset by a full pixel) has a deeper meaning: The cloud edges are indeed between the pixels which have been identified as a cloud.
If the method would be applied exactly as above, \(E\) would be one entry less than the number of pixels. In order to make the following method work properly, we need to extend the edge information to before and after the first and last pixel. We’ll set \(E_0 = C_0\) (we only start with a cloud if the first pixel is a cloudy one, but don’t end a cloud before the first pixel) and \(E_N = -C_{N-1}\) (we end a cloud if the last pixel is a cloudy one, but don’t start a cloud after the last pixel).
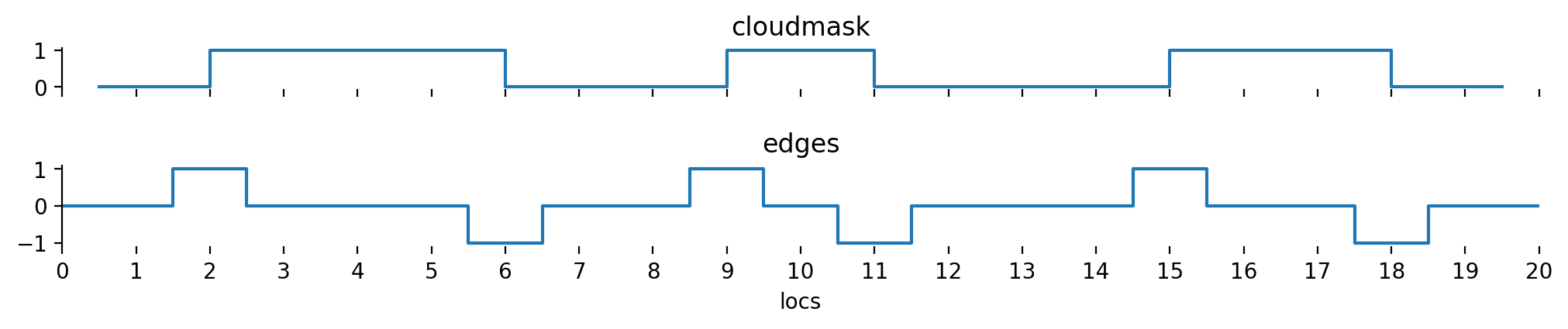
Let’s also have a look at a graphical representation of what we have done so far:
Based on \(E\), we can extract a boolean array of cloud start (\(E == 1\)) and cloud end (\(E == -1\)) locations.
Based on these two boolean arrays, in particular the indices of the True entries, we can compute a cloud length in index space:
def cloud_lengths(cloudmask):
cloudmask = np.asarray(cloudmask, dtype="int")
edges = np.concatenate([cloudmask[:1], cloudmask[1:] - cloudmask[:-1], -cloudmask[-1:]])
starts, = np.where(edges == 1) # note that np.where returns a one-element tuple
ends, = np.where(edges == -1) # we unpack it using ,=
return ends - starts
Let’s try our new method based on the cloud mask from our example.
cloud_lengths(cloudmask)
array([4, 2, 3])
It works just as we expected.
Segment statistics#
Now that we know how to separate consecutive cloudy segments from our trajectory data, it might be useful to aggregate data for each cloudy segment. We want to do this using a similar approach, but one thing is different: we do need to care about each individual data point within a cloud, so we need to do many aggregations across differently sized sets of data. That is not something which seems to be expressible in a vectorized way at first sight. Nonetheless, there are some ways of accomplishing our goal.
One approach to this problem is the split - apply - combine approach, which is what among others, xarray, pandas and SQL provide.
The idea is that we group our data into common sections (those would be one group per individual cloud) and then run a function (which reduces some data to a single value) on each group individually.
The return values from each group are combined into a final result.
While this is a neat way to think about the problem, it has a major drawback when applied to xarray or pandas: it is really slow.
The method is just a sneaky way of running a for loop over all clouds and thus deliberately avoids the use of numpy to speed things up.
But we can still look at the structure of such an operation and then think about how we could do something similar with better performance.
So first, we need some way of identifying each individual cloud.
We’ll do this by introducing another array.
We can create such an array by applying the cumulative sum on the absolute value of the edges \(E\).
This will also assign individual identifiers to cloud free parts, but that’s fine, we can filter them out afterwards.
For now, we’ll call this array section_id to distinguish between all data split up in sections and the (cloud-only) segments mentioned before.
If we can then find a way to accumulate data into individual bins based on the section_id, we should be ready to compute further statistics.
section_ids = np.cumsum(np.abs(edges[:-1]))
Let’s have a look at the whole process idea in a graphical way:
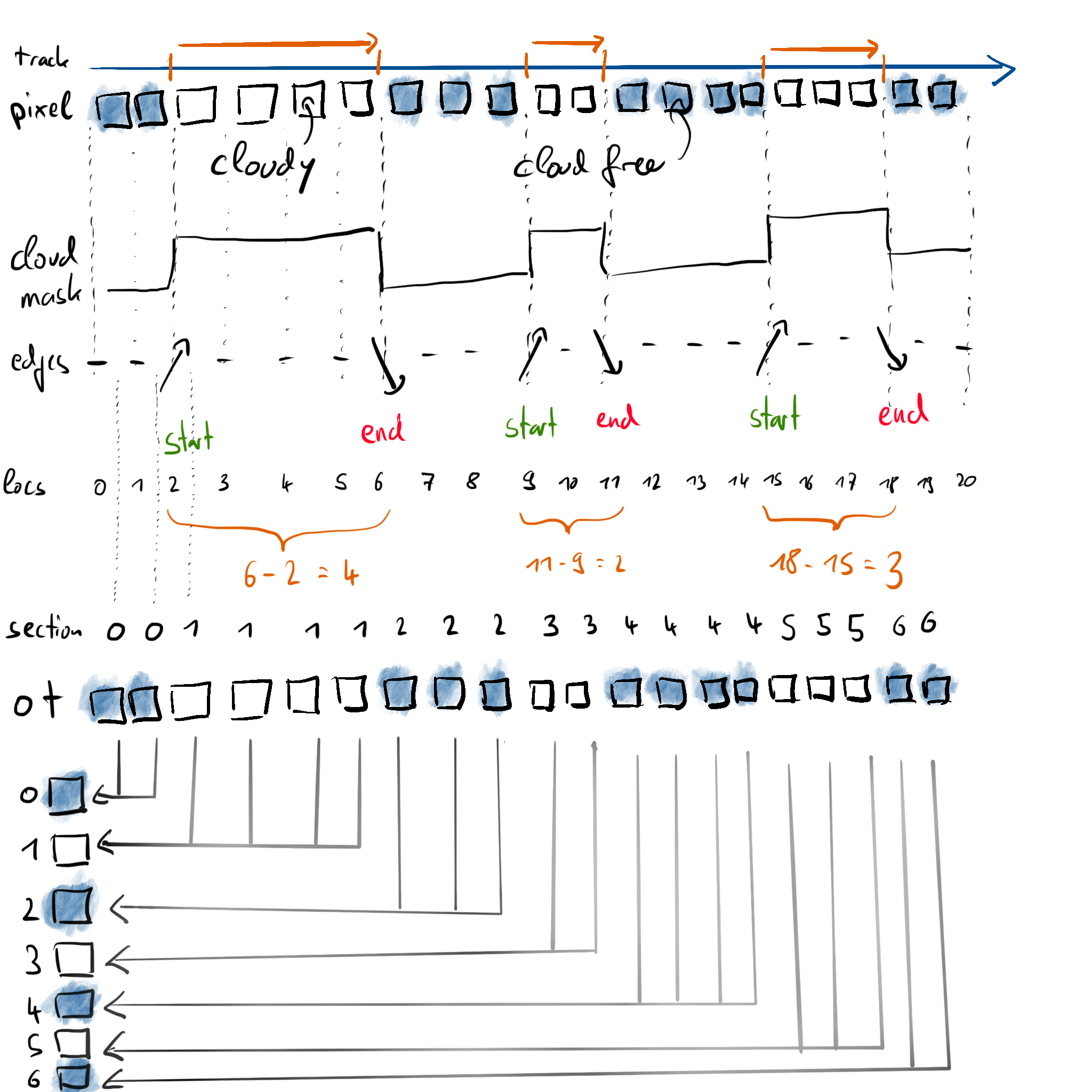
Let’s say we want to compute the average optical thickness of each detected cloud segment. For this example, we assume the following optical thickness per source pixel:
ot = np.array([0., 0., 1., 2., 4., 5., 0., 0., 0., 2., 2., 0., 0., 0., 0., 1., 1., 1., 0., 0.])
We already know how many pixels are part of the cloud (the cloud length from above), so we only need the sum of the optical thickness within the segment in order to compute the mean. Thus, what we conceptually want to do is:
ot_sum[section_ids] += ot
But += will only work correctly if none of the index values from section_ids are duplicated, which definitely is not the case, as we designed section_ids such that it will contain the same value for every pixel within the same cloud.
Fortunately numpy provides ufunc.at which solves this exact problem.
The at method is available for all scalar universal functions of numpy which take two arguments and is intended for repeated in-place application of the given universal function.
Addition (add) is such a scalar ufunc with two arguments, so we can use np.add.at in this case:
ot_sum = np.zeros(np.max(section_ids) + 1)
np.add.at(ot_sum, section_ids, ot)
ot_sum
array([ 0., 12., 0., 4., 0., 3., 0.])
Note
Observe how
np.add.at(ot_sum, section_ids, ot)
can be used as a direct replacement for
ot_sum[section_ids] += ot
However, though the latter is simpler to understand, only np.add.at will provide the correct results.
As indicated above, the result will contain values for each clear and cloudy segment.
In order to compute the final mean cloud optical thickness, we simply can use every odd element of ot_sum (those are the cloudy pieces) and divide them by cloud length:
ot_sum[1::2] / cloud_lengths(cloudmask)
array([3., 2., 1.])
which is indeed the average optical thickness of the three detected clouds.
Note
While taking every odd element might seem to be a special case (what if the first pixel ist cloudy?), it is in fact the general case. As we’ve set \(E_0 = C_0\), the very first edge entry will mark the start of a cloud in this case and thus the first section_id (the cumulative sum) will be 1 in stead of 0 and thus odd as well.
Further generalizations#
If we would have computed the cloud lengths not based on the index locations of the cloud edges, but instead based on the position along the flight path (e.g. in meters), this method can be generalized to unevenly spaced datasets. Furthermore, if we would multiply the pixel optical thickness by the size of the pixel, the same method as above could be used to compute distance weighted averages of cloud parameters.